(See related pages)
Chapter 1 Purpose The purpose of this chapter is to introduce the student to a variety of strategic issues that arise in the manufacturing function of the firm. Key Points 1. Manufacturing matters. This writer contends that the loss of the manufacturing base in the U.S. economy is not healthy and will eventually lead to an overall loss in the standard of living and quality of life in this country. It counters the argument that our evolution into a service economy is a natural and healthy thing.2. Strategic dimensions. Along with cost and/or product differentiation, other dimensions along which firms distinguish themselves include (a) quality, (b) delivery speed, (c) delivery reliability, and (d) flexibility. 3. Classical view. The classical literature on manufacturing strategy indicates that strategy should be viewed in relation to one or more of the following issues: (a) time horizon, (b) focus, (c) evaluation, and (d) consistency. 4. Global competition. How do we measure our success and economic health on a global scale? One way is to examine classical measures of relative economic strength, which include (a) balance of trade, (b) share of world exports, (c) creation of jobs, and (d) cost of labor. However, such macro measures do not adequately explain why certain countries dominate certain industries. National competitive advantage is a consequence of several factors (factor conditions, demand conditions, related and supporting industries, firm strategy structure, and rivalry), although productivity also plays an important role. 5. Strategic initiatives. We discuss several strategic initiatives that have allowed many companies to shine in their respective arenas. These include (a) business process reengineering, (b) just-in-time manufacturing and purchasing systems, (c) time-based competition, and (d) competing on quality. 6. Product and process life cycles. Most of us understand that products have natural life cycles: start-up, rapid growth, maturation, stabilization, or decline. However, it is rarely recognized that processes too have life cycles. Initially, new manufacturing processes have the characteristics of a job shop. As the process matures, automation is introduced. In the mature phases of a manufacturing process, most major operations are automated. A firm needs to match the phases of product and process life cycles to be the most successful in its arena. 7. Learning and experience curves. These are helpful in forecasting the decline in unit cost of a manufacturing process as one gains experience with the process. Learning curves are more appropriate when modeling the learning of an individual worker, and experience curves are more appropriate when considering an entire industry. 8. Capacity growth planning. Another important strategic issue in operations is determining the timing and sizing of new capacity additions. Simple models (make or buy problem) and more complex exponential growth models are explored in Section 1.11. In addition, some of the factors that determine appropriate location of new facilities is explored. Chapter 2 Purpose To present and illustrate the most important methods for forecasting demand in the context of operations planning.Key Points 1. Characteristics of forecasts.
4. Evaluation of forecasting methods. The forecast error in any period, et, is the difference between the forecast for period t and the actual value of the series realized for period t (et = Ft - Dt). Three common measures of forecast error are MAD (average of the absolute errors over n periods), MSE (the average of the sum of the squared errors over n periods), and MAPE (the average of the percentage errors over n periods). 5. Methods for forecasting stationary time series. We consider two forecasting methods when the underlying pattern of the series is stationary over time: moving averages and exponential smoothing. A moving average is simply the arithmetic average of the N most recent observations. Exponential smoothing forecasts rely on a weighted average of the most recent observation and the previous forecast. The weight applied to the most recent observation is α, where 0 < α < 1, and the weight applied to the last forecast is 1 - α. Both methods are commonly used in practice, but the exponential smoothing method is favored in inventory control applications—especially in large systems—because it requires much less data storage than does moving averages. 6. Methods for forecasting series with trend. When there is an upward or downward linear trend in the data, two common forecasting methods are linear regression and double exponential smoothing via Holt's method. Linear regression is used to fit a straight line to past data based on the method of least squares, and Holt's method uses separate exponential smoothing equations to forecast the intercept and the slope of the series each period. 7. Methods for forecasting seasonal series. A seasonal time series is one that has a regular repeating pattern over the same time frame. Typically, the time frame would be a year, and the periods would be weeks or months. The simplest approach for forecasting seasonal series is based on multiplicative seasonal factors. A multiplicative seasonal factor is a number that indicates the relative value of the series in any period compared to the average value over a year. Suppose a season consists of 12 months. A seasonal factor of 1.25 for a given month means that the demand in that month is 25 percent higher than the mean monthly demand. Winter's method is a more complex method based on triple exponential smoothing. Three distinct smoothing equations are used to forecast the intercept, the slope, and the seasonal factors each period. 8. Other considerations. Economic forecasting and time series analysis are very rich areas of research. When one has a long history of data, far more sophisticated methods are available. The so-called Box-Jenkins methods rely on evaluation and examination of the autocorrelation function to determine a suitable model. Filtering theory, originally developed in the context of problems in communications, can often be adapted to forecast economic time series. Two of the better known filters are Wiener and Kalman filters. In recent years, there has been a surge of interest in neural nets, a computer search-based method. None of these techniques are amenable to automatic forecasting, and they all require a knowledgeable and sophisticated user. Monte Carlo simulation is another useful tool for forecasting in complex environments. The chapter concludes with a discussion of several forecasting issues that arise in the context of inventory control. Chapter 3 Purpose To develop techniques for aggregating units of production, and determining suitable production levels and workforce levels based on predicted demand for aggregate units.Key Points 1. Aggregate units of production. This chapter could also have been called Macro Production Planning, since the purpose of aggregating units is to be able to develop a top-down plan for the entire firm or for some subset of the firm, such as a product line or a particular plant. For large firms producing a wide range of products or for firms providing a service rather than a product, determining appropriate aggregate units can be a challenge. The most direct approach is to express aggregate units in some generic measure, such as dollars of sales, tons of steel, or gallons of paint. For a service, such as provided by a consulting firm or a law firm, billed hours would be a reasonable way of expressing aggregate units.2. Aspects of aggregate planning. The following are the most important features of aggregate planning:
5. The linear decision rule. The aggregate planning concept had its roots in the work of Holt, Modigliani, Muth, and Simon (1960) who developed a model for Pittsburgh Paints (presumably) to determine their workforce and production levels. The model used quadratic approximations for the costs, and obtained simple linear equations for the optimal policies. This work spawned the later interest in aggregate planning. 6. Modeling management behavior. Bowman (1963) considered linear decision rules similar to those derived by Holt, Modigliani, Muth, and Simon except that he suggested fitting the parameters of the model based on management's actions, rather than prescribing optimal actions based on cost minimization. This is one of the few examples of a mathematical model used to describe human behavior in the context of operations planning. 7. Disaggregating aggregate plans. While aggregate planning is useful for providing approximate solutions for macro planning at the firm level, the question is whether these aggregate plans provide any guidance for planning at the lower levels of the firm. A disaggregation scheme is a means of taking an aggregate plan and breaking it down to get more detailed plans at lower levels of the firm. Chapter 4 Purpose To consider methods for controlling individual item inventories when product demand is assumed to follow a known pattern (that is, demand forecast error is zero).Key Points 1. Classification of inventories
 6. The EOQ with finite production rate. This is an extension of the basic EOQ model to take into account that when items are produced internally rather than ordered from an outside supplier, the rate of production is finite rather than infinite, as would be required in the simple EOQ model. We show that the optimal size of a production run now follows the formula  7. Quantity discounts. We consider two types of quantity discounts: all-units and incremental discounts. In the case of all-units discounts, the discount is applied to all the units in the order, while in the case of incremental discounts, the discount is applied to only the units above the break point. The all-units case is by far the most common in practice, but one does encounter incremental discounts in industry. In the case of all-units discounts, the optimization procedure requires searching for the lowest point on a broken annual cost curve. In the incremental discounts case, the annual cost curve is continuous, but has discontinuous derivatives. 8. Resource-constrained multiple product systems. Consider a retail store that orders many different items, but cannot exceed a fixed budget. If we optimize the order quantity of each item separately, then each item should be ordered according to its EOQ value. However, suppose doing so exceeds the budget. In this section, a model is developed that explicitly takes into account the budget constraint and adjusts the EOQ values accordingly. In most cases, the optimal solution subject to the budget constraint requires an iterative search of the Lagrange multiplier. However, when the condition c1/h1 = c2/h2 = … = cn/hn is met, the optimal order quantities are a simple scaling of the optimal EOQ values. Note that this problem is mathematically identical to one in which the constraint is on available space rather than available budget. 9. EOQ models for production planning. Suppose that n distinct products are produced on a single production line or machine. Assume we know the holding costs, order costs, demand rates, and production rates for each of the items. The goal is to determine the optimal sequence to produce the items, and the optimal batch size for each of the items to meet the demand and minimize costs. Note that simply setting a batch size for each item equal to its EOQ value (that is, optimal lot size with a finite production rate), is likely to be suboptimal since it is likely to result in stock-outs. The problem is handled by considering the optimal cycle time, T, where we assume we produce exactly one lot of each item each cycle. The optimal size of the production run for item j is simply Qj = λjT, where T is the optimal cycle time. Finding T is nontrivial, however. Chapter 5 Purpose To understand how one deals with uncertainty (randomness) in the demand when computing replenishment policies for a single inventory item.Key Points 1. What is uncertainty and when should it be assumed? Uncertainty means that demand is a random variable. A random variable is defined by its probability distribution, which is generally estimated from a past history of demands. In practice, it is common to assume that demand follows a normal distribution. When demand is assumed normal, one only needs to estimate the mean, μ, and variance, σ2. Clearly, demand is uncertain to a greater or lesser extent in all real world applications. What value, then, does the analysis of Chapters 3 and 4 have, where demand was assumed known? Chapter 3 focused on systematic or predictable changes in the demand pattern, such as peaks and valleys. Chapter 4 results for single items are useful if the variance of demand is low relative to the mean. In this chapter we consider items whose primary variation is due to uncertainty rather than predictable causes.If demand is described by a random variable, it is unclear what the optimization criterion should be, since the cost function is a random variable as well. To handle this, we assume that the objective is to minimize expected costs. The use of the expectation operator is justified by the law of large numbers from probability, since an inventory control problem invariably spans many planning periods. The law of large numbers guarantees that the arithmetic average of the incurred costs and the expected costs grow close as the number of planning periods gets large. 2. The newsboy model. Consider a news vendor that decides each morning how many papers to buy to sell during the day. Since daily demand is highly variable, it is modeled with a random variable, D. Suppose that Q is the number of papers he purchases. If Q is too large, he is left with unsold papers, and if Q is too small, some demands go unfilled. If we let co be the unit overage cost, and cu be the unit underage cost, then we show that the optimal number of papers he should purchase at the start of a day, say Q*, satisfies: F(Q*) = cu / (cu + co) where F(Q*) is the cumulative distribution function of D evaluated at Q* (which is the same as the probability that demand is less than or equal to Q*).3. Lot size–reorder point systems. The newsboy model is appropriate for a problem that essentially restarts from scratch every period. Yesterday's newspaper has no value in the market, save for the possible scrap value of the paper itself. However, most inventory control situations that one encounters in the real world are not like this. Unsold items continue to have value in the marketplace for many periods. For these cases we use an approach that is essentially an extension of the EOQ model of Chapter 4. The lot size–reorder point system relies on the assumption that inventories are reviewed continuously rather than periodically. That is, the state of the system is known at all times. The system consists of two decision variables: Q and R. Q is the order size and R is the reorder point. That is, when the inventory of stock on hand reaches R, an order for Q units is placed. The model also allows for a positive order lead time, 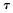
4. Service levels in (Q, R) systems. We assume two types of service: Type 1 service is the probability of not stocking out in the lead time and is represented by the symbol α. Type 2 service is the proportion of demands that are filled from stock (also known as the fill rate) and is represented by the symbol β. Finding the optimal (Q, R) subject to a Type 1 service objective is very easy. One merely finds R from F(R) = α and sets Q = EOQ. Unfortunately, what one generally means by service is the Type 2 criterion, and finding (Q, R) in that case is more difficult. For Type 2 service, we only consider the normal distribution. The solution requires using standardized loss tables, L(z), which are supplied in the back of the book. As with the cost model, setting Q = EOQ and solving for R will usually give good results if one does not want to bother with an iterative procedure. In this chapter, we consider the link between inventory control and forecasting, and how one typically updates estimates of the mean and standard deviation of demand using exponential smoothing. The section concludes with a discussion of lead time variability, and how that additional uncertainty is taken into account. 5. Periodic review systems under uncertainty. The newsboy model treats a product that perishes quickly (after one period). However, periodic review models also make sense when unsold product can be used in future periods. In this case the form of the optimal policy is known as an (s, S) policy. Let u be the starting inventory in any period. Then the (s, S) policy is If u ≤ s, order to S (that is, order S - u).Unfortunately, finding the optimal values of (s, S) each period is much more difficult than finding the optimal (Q, R) policy, and is beyond the scope of this book. We also briefly discuss service levels in periodic review systems. 6. Multiproduct systems. Virtually all inventory control problems occurring in the operations planning context involve multiple products. One issue that arises in multiproduct systems is determining the amount of effort one should expend managing each item. Clearly, some items are more valuable to the business than others. The ABC classification system is one means of ranking items. Items are sequenced in decreasing order of annual dollar volume of sales or usage. Ordering the items in this way, and graphing the cumulative dollar volume gives an exponentially increasing curve known as a Pareto curve. Typically, 20 percent of the items account for 80 percent of the annual dollar volume (A items), the next 30 percent of the items typically account for the next 15 percent of the dollar volume (B items), and the final 50 percent of the items account for the final 5 percent of the dollar volume (C items). A items should receive the most attention. Their inventory levels should be reviewed often, and they should carry a high service level. B items do not need such close scrutiny, and C items are typically ordered infrequently in large quantities. 7. Other issues. The discussion of stochastic inventory models in this chapter barely reveals the tip of the iceberg in terms of the vast quantity of research done on this topic. Two important areas of research are multi-echelon inventory systems, and perishable inventory systems. A multi-echelon inventory system is one in which items are stored at multiple locations linked by a network. Supply chains, discussed in detail in Chapter 6, are such a system. Another important area of research are items that change during storage, thus affecting their useful lifetime. One class of such items are perishable items. Perishable items have a fixed lifetime known in advance, and include food, pharmaceuticals and photographic film. A related problem is managing items subject to obsolescence. Obsolescence differs from perishability in that the useful lifetime of an item subject to obsolescence cannot be predicted in advance. Mathematical models for analyzing such problems are quite complex and well beyond the scope of this book. Chapter 6 Purpose To understand what a modern supply chain is, how supply chains are organized and managed, and to review the newest developments in this important area.Key Points 1. What is a supply chain? A supply chain is the entire network related to the activities of a firm that links suppliers, factories, warehouses, stores, and customers. It requires management of goods, money, and information among all the relevant players. The term supply chain management (SCM) is relatively new, evidently having emerged from the experiences of Proctor and Gamble (P&G) in the late 1980s when tracking the flow of Pampers through the distribution channel. However, managing the flow of goods was an issue long before the nomenclature supply chain management was coined. Traditionally called logistics, supply management issues have been present since the industrial revolution. Why the sudden interest in supply chains? Traditionally, firms focused on manufacturing. As a result, manufacturing has become relatively efficient, and there are fewer opportunities to trim costs from the manufacturing function. However, significant opportunities still exist for cutting costs from the supply chain.2. The transportation problem. The transportation problem is one of the early applications of linear programming. Assume m production facilities (sources) and n demand points (sinks). The unit cost of shipping from every source to every sink is known, and the objective is to determine a shipping plan that satisfies the supply and demand constraints at minimum cost. The linear programming formulation of the transportation problem has been successfully solved with hundreds of thousands of variables and constraints. A generalization of the transportation problem is the transshipment problem. Here intermediate nodes can be used for storage as well as be demand or supply points. Transshipment problems can be also be solved with linear programming. 3. Distribution resource planning and routing in supply chains. In Section 6.5, we provide a brief discussion of distribution resource planning (DRP). DRP is the application of materials requirements planning (MRP, discussed in Chapter 7) to problems of distribution. The method has the advantage over the reorder point (ROP) approach discussed in Chapter 5 in that it allows for predictable variation in the demand pattern. However, it ignores the unsystematic variation (randomness) explicitly accounted for in ROP analysis. Section 6.6 gives a brief introduction to problems in vehicle routing. Consider a delivery truck that must make deliveries to several customers. The objective is to find the optimal sequence of deliveries that minimizes the total distance required. This problem is known as the traveling salesman problem, and turns out to be very difficult to solve optimally. The calculations required to find the optimal solution grow exponentially with the problem size (known mathematically as an NP hard problem). In this section, we present a simple heuristic for obtaining approximate solutions known as the savings method. 4. Designing products for supply chain efficiency. "Thinking outside the box" has become a cliché. It means looking at a problem in a new way, often not taking constraints at face value. An example of thinking outside the box is postponement in supply chains. The first application of this idea is due to Benetton, a well-known manufacturer of fashion knitwear. Benetton must predict consumers' color preferences in advance of the selling season. Because wool is dyed first and then later weaved into sweaters, the color mix must be decided upon well in advance. If their predictions about consumers' color preferences are wrong (which they invariably are), popular colors would sell out quickly and unpopular colors would sit on the shelves. Their solution was to reverse the order of the weaving and dying operations. Sweaters were woven from undyed wool (gray stock) and then dyed to specific colors as late as possible. This provided Benetton with more time to observe which colors were selling best. Hewlett Packard discovered a similar solution in their printer division. Printers must be configured for local markets due to language and other differences. By producing "gray stock" printers that had all common parts, and then configuring export printers on site in local markets, they were able to delay product differentiation and better balance their inventories. Another example of designing products for supply chain efficiency is Ikea. Ikea is a Swedish-based firm that sells inexpensive home furnishings. To reduce costs Ikea designs their furniture to be easily stored directly at the retail outlets. This means that customers can take their purchases with them, thus removing the long delays and customization required by more traditional furniture outlets. 5. The role of information in supply chains. As has been noted, a supply chain involves the transfer of goods, money, and information. Modern supply chain management seeks to eliminate the inefficiencies that arise from poor information flows. One way to ameliorate this problem is by way of vendor-managed inventories. Both Wal-Mart and Barilla (an Italian-based producer of pasta) have benefited from vendor-managed inventory systems. In these situations, the vendors, rather than the retailers, are responsible for keeping inventory on the shelves. As noted earlier, the term supply chain management arose from the experience of P&G tracking the variability of sales of Pampers through the various stages of the supply chain. What P&G noticed was that even though the consumer demand for the final product was pretty even over time, there were wide swings in the pattern of orders of Pampers to the factory. Several have speculated about the causes of this phenomenon. A similar consequence appears when playing the Beer Game, a simulation originally conceived by Jay Forrester. Electronic commerce and electronic data interchange have gone a long way to streamline supply chain operations by improving the speed and efficiency of transactions. EDI includes both proprietary data exchange systems and Web based transactions systems. 6. Multilevel distribution systems. Typically in large systems, stock is stored at multiple locations. Distribution centers (DCs) receive stock from plants and factories and then ship to either smaller local DCs or directly to stores. Some of the advantages of employing DCs include economies of scale, tailoring the mix of product to a particular region or culture, and safety stock reduction via risk pooling. 7. Designing the supply chain in a global environment. Today, most firms are multinational. Products are designed for, and shipped to, a wide variety of markets around the world. As an example, consider the market for automobiles. Fifty years ago, virtually all the automobiles sold in the United States were produced here. Today, that number is probably closer to 50 percent. Global market forces are shaping the new economy. Vast markets, such as China, are now emerging, and the major industrial powers are vying for a share. Technology, cost considerations, and political and macroeconomic forces have driven globalization. Selling in diverse markets presents special problems for supply chain management. Chapter 7 Purpose To understand the push and pull philosophies in production planning and compare MRP and JIT methods for scheduling the flow of goods in a factory.Key Points 1. Push versus pull. There are two fundamental philosophies for moving material through the factory. A push system is one in which production planning is done for all levels in advance. Once production is completed, units are pushed to the next level. A pull system is one in which items are moved from one level to the next only when requested. Materials requirements planning (MRP) is the basic push system. Based on forecasts for end items over a specified planning horizon, the MRP planning system determines production quantities for each level of the system. It relies on the so-called explosion calculus, which requires knowledge of the gozinto factor (i.e., how many of part A are required for part B), and production lead times. The earliest of the pull systems is kanban developed by Toyota, which has exploded into the just-in-time (JIT) and lean production movements. Here the fundamental goal is to reduce work-in-process to a bare minimum. To do so, items are only moved when requested by the next higher level in the production process. Each of the methods has particular advantages and disadvantages.2. MRP basics. The MRP explosion calculus is a set of rules for converting a master production schedule (MPS) to a build schedule for all the components comprising the end product. The MPS is a production plan for the end item or final product by period. It is derived from the forecasts of demand adjusted for returns, on hand inventory, and the like. At each stage in the process, one computes the production amounts required at each level of the production process by doing two basic operations: (1) offsetting the time when production begins by the lead time required at the current level and (2) multiplying the higher-level requirement by the gozinto factor. The simplest production schedule at each level is lot-for-lot (L4L), which means one produces the number of units required each period. However, if one knows the holding and setup cost for production, it is possible to construct a more cost efficient lot-sizing plan. Three heuristics we consider are (1) EOQ lot sizing, (2) the Silver–Meal heuristic, and (3) the least unit cost heuristic. Optimal lot sizing requires dynamic programming and is discussed in Appendix 7–A. We also consider lot sizing when capacity constraints are explicitly accounted for. This problem is difficult to solve optimally, but can be approximated efficiently. MRP as a planning system has advantages and disadvantages over other planning systems. Some of the disadvantages include (1) forecast uncertainty is ignored; (2) capacity constraints are largely ignored; (3) the choice of the planning horizon can have a significant effect on the recommended lot sizes; (4) lead times are assumed fixed, but they should depend on the lot sizes; (5) MRP ignores the losses due to defectives or machine downtime; (6) data integrity can be a serious problem; and (7) in systems where components are used in multiple products, it is necessary to peg each order to a specific higher-level item. 3. JIT basics. The JIT philosophy grew out of the kanban system developed by Toyota. Kanban is the Japanese word for card or ticket. Kanban controls the flow of goods in the plant by using a variety of different kinds of cards. Each card is attached to a palette of goods. Production cannot commence until production ordering kanbans are available. This guarantees that production at one level will not begin unless there is demand at the next level. This prevents work-in-process inventories from building up between work centers when a problem arises anywhere in the system. Part of what made kanban so successful at Toyota was the development of single minute exchange of dies (SMED), which reduced changeover times for certain operations from several hours to several minutes. Kanban is not the only way to implement a JIT system. Information flows can be controlled more efficiently with a central information processor than with cards. 4. Comparison of JIT and MRP. JIT has several advantages and several disadvantages when compared with MRP as a production planning system. Some of the advantages of JIT include (1) reduce work-in-process inventories, thus decreasing inventory costs and waste, (2) easy to quickly identify quality problems before large inventories of defective parts build up, and (3) when coordinated with a JIT purchasing program, ensures the smooth flow of materials throughout the entire production process. Advantages of MRP include (1) the ability to react to changes in demand, since demand forecasts are an integral part of the system (as opposed to JIT which does no look-ahead planning); (2) allowance for lot sizing at the various levels of the system, thus affording the opportunity to reduce setups and setup costs; and (3) planning of production levels at all levels of the firm for several periods into the future, thus affording the firm the opportunity to look ahead to better schedule shifts and adjust workforce levels in the face of changing demand. Chapter 8 Purpose To gain an understanding of the key methods and results for sequence scheduling in a job shop environment.Key Points 1. The job shop scheduling problem. A job shop is a set of machines and workers who use the machines. Jobs may arrive all at once or randomly throughout the day. For example, consider an automotive repair facility. On any day, one cannot predict in advance exactly what kinds of repairs will come to the shop. Different jobs require different equipment and possibly different personnel. A senior mechanic might be assigned to a complex job, such as a transmission replacement, while a junior mechanic would be assigned to routine maintenance. Suppose the customers bring their cars in first thing in the morning. The shop foreman must determine the sequence in which to schedule the jobs in the shop to make the most efficient use of the resources (both human and machine) available. The relevant characteristics of the sequencing problem include
4. Sequence scheduling in a stochastic environment. The problems alluded to previously assume all information is known with certainty. Real problems are more complex in that there is generally some type of uncertainty present. One source of uncertainty could be the job times. In that case, the job times, say t1, t2, . . . , tn, are assumed to be independent random variables with α known distribution function. The optimal sequence for a single machine in this case is very much like scheduling the jobs in SPT order based on expected processing times. When scheduling jobs with uncertain processing times on multiple machines, one must assume that the distribution of job times follows an exponential distribution. The exponential distribution is the only one possessing the so-called memoryless property, which turns out to be crucial in the analysis. When the objective is to minimize the expected makespan (that is, the total time to complete all jobs), it turns out that the longest expected processing time (LEPT) first rule is optimal. Another source of uncertainty in a job shop is the order in which jobs arrive to the shop. In the automotive job shop example, we assumed that jobs arrived all at once at the beginning of the day. However, in a factory setting, jobs are likely to arrive at random times during the day. In this case, queueing theory can shed some light on how much time elapses from the point a job arrives until its completion. This section outlines several results under assumptions of FCFS, LCFS, and SPT sequencing. 5. Line balancing. Another problem that arises in the factory setting is that of balancing an assembly line. While line balancing is not a sequence scheduling problem found in a job shop environment, it is certainly a scheduling problem arising within the plant. Assume we have an item flowing down an assembly line and that a total of n tasks must be completed on the item. The problem is to determine which tasks should be placed where on the line. Typically, an assembly line is broken down into stations and some subset of tasks is assigned to each station. The goal is to balance the time required at each station while taking into account the precedence relationships existing among the individual tasks. Optimal line balances are difficult to find. We consider one heuristic method, which gives reasonable results in most circumstances. Following this chapter is a supplement on queuing theory, which provides a brief summary of the most significant results in this area. Chapter 9 Purpose To understand how mathematical and graphical techniques are used to assist with the task of scheduling complex projects in an organization.Key Points 1. Project representation and critical path identification. There are two convenient graphical techniques for representing a project. One is a Gantt chart. The Gantt chart was used in Chapter 8 to represent sequence schedules on multiple machines. However, representing a project as a Gantt chart has one significant drawback. Precedence relationships (that is, specifying which activities must precede other activities) are not displayed. To overcome this inadequacy, we represent a project as a network rather than a Gantt chart. A network is a set of nodes and directed arcs. Nodes correspond to milestones in the project (completion of some subset of activities), and arcs to specific activities.In the network representation, the goal is to identify the critical, or longest, path. In the spirit of "a chain is only as strong as its weakest link," a project cannot be completed until all the activities along the critical path are completed. The length of the critical path gives the earliest completion time of the project. Activities not along the critical path (noncritical activities) have slack time—that is, they can be delayed without necessarily delaying the project. In Section 9.2, we present an algorithm for identifying the critical path in a network. (This is only one of several solution methods.) 2. Time costing methods. Consider a construction project. Each additional day that elapses results in higher costs. These costs include direct labor costs for the personnel involved in the project, costs associated with equipment and material usage, and overhead costs. Let us suppose one has the option of decreasing the time of selected activities, but also at some cost. As the times required for activities along the critical path are decreased, the expediting costs increase but the costs proportional to the project time decrease. Hence, there is some optimal time for the project that balances these two competing costs. The problem of cost-optimizing the time of a project can be solved manually or via linear programming. 3. Project scheduling with uncertain activity times. In some projects, such as construction projects, the time required to do specific tasks can be predicted accurately in advance. In most cases, past experience can be used as an accurate guide, even for novel projects. However, this is not the case with research projects. When undertaking the solution of an unsolved problem, or designing an entirely new piece of equipment, it is difficult, if not impossible, to predict activity times accurately in advance. A more reasonable assumption is that activity times are random variables with some specified distribution. A method that explicitly allows for uncertain activity times is the project evaluation and review technique (PERT). This technique was developed by the Navy to assist with planning the Polaris submarine project in 1958. The PERT approach is to assume that planners specify for each activity a minimum time, a, a maximum time, b, and a most likely time, m, for each activity. These estimates are then used to construct a beta distribution for each activity time. The PERT assumption is that the critical path will be the path with the longest expected completion time (which is not necessarily the case), and the total project time will be the sum of the times along the critical path. Assuming activity times are independent random variables, one computes the mean and variance along the critical path by summing the means and variances of the activity times. The central limit theorem is then used to justify the assumption that the project completion time has a normal distribution with mean and variance computed as previously described. Note that this is only an approximation, since there is no guarantee that the path with the longest expected completion time will turn out to be the critical path. Determining the true distribution of project completion time appears to be a very difficult problem in general. However, PERT provides a reasonable approximation and is certainly an improvement over the deterministic critical path method (CPM). 4. Resource considerations. Consider a department within a firm in which several projects are simultaneously ongoing. Suppose that each member of the department is working on more than one project at a time. Since the time of each worker is limited, each project manager is competing for a limited resource, namely, the time of the workers. One could imagine other cases where the limited resource might be a piece of equipment, such as a single supercomputer in a company. In these cases, incorporating resource constraints into the project planning function can be quite a challenge. We present an example of balancing resources, but know of no general-purpose method for solving this problem. Chapter 10 Purpose To understand the major issues faced by a firm when designing and locating new facilities, and to learn the quantitative techniques for assisting with the decision making process.Key Points 1. Fundamentals. Before deciding on the appropriate layout for a new facility, whether it be a factory, hospital, theme park, or anything else, one must first study the patterns of flow. The simplest flow pattern is straight-line flow, as might be encountered on an assembly line. Other patterns include U flow, L flow, serpentine flow, circular flow, and S flow. Another issue is desirability or undesirability of locating operations near each other. For example, in a hospital, the emergency room must be near the hospital entrance, and the maternity ward should be close to the area where premature babies are cared for. A graphical technique for representing the relative desirability of locating two facilities near each other is the activity relationship chart (or rel chart). From-to charts give the distances between activities, which can be used to compute costs associated with various layouts.2. Types of layouts. In the factory setting, the appropriate type of layout depends on the manufacturing environment and the characteristics of the product. A fixed position layout is appropriate when building large items such as planes or ships that are difficult and costly to move. Workstations are located around the object, which remains stationary. More typical is the product layout where machines or workstations are organized around the sequence of operations required to produce the product. Product layouts are most typical for mass production. In the case of small- to medium-sized companies, a process layout makes more sense. Here one groups similar machines or similar processes together. Finally, layouts based on group technology might be appropriate. In this case, machines might be grouped into machine cells where each cell corresponds to a part family or group of part families. 3. Computerized layout techniques. For large complex factories or service facilities, determining the best layout manually is impractical. There are several computerized layout techniques available to assist with this function. They include CRAFT, COFAD, ALDEP, CORELAP, and PLANET. All of these methods are intended for the factory setting and share the objective of minimizing materials handling costs. Both CRAFT and COFAD are based on the principle of improvement. This means that the user must specify an initial layout. From there, one considers pairwise interchanges of departments and chooses the one with the largest improvement. Both ALDEP, CORELAP, and PLANET are construction routines rather than improvement routines. Layouts are determined from scratch, and there is no requirement that the user specify an initial layout. There is some controversy regarding whether human planners or computer programs produce better layouts. In one study where groups of 20 chosen from 74 people trained in layout techniques were compared with computerized layouts, the humans fared much better. Others criticized this study on the grounds that most layout departments are not that well staffed. 4. Flexible manufacturing systems. A flexible manufacturing system (FMS) is a collection of numerically controlled machines connected by a computer-controlled materials flow system. Typical flexible manufacturing systems are used for metal cutting and forming operations and certain assembly operations. Because the machines can be programmed, the same system can be used to produce a variety of different parts. Flexible manufacturing systems tend to be extremely expensive (some costing upwards of $10 million). As a result, the added flexibility may not be worth the cost. While the FMS can have many advantages (reducing work-in-process inventory, increased machine utilization, flexibility), these advantages are rarely justified by the high cost of these systems. An alternative that is more popular is flexible manufacturing cells. These are smaller than full-blown systems, but still provide more flexibility than single-function equipment. 5. Locating new facilities. Where to locate a new facility is a complex and strategically important problem. Hospitals need to be close to high-density population centers, and airports need to be near large cities, but not too near because of noise pollution. New factories are often located outside the United States to take advantage of the lower labor costs overseas. But these savings might come at a high price. Political instability, unfavorable exchange rates, infrastructure deficiencies, and long lead times are a few of the problems that arise from locating facilities abroad. Often such decisions are more strategic than tactical and require careful weighing of the advantages and disadvantages at the level of top management. However, in cases where the primary objective is to locate a facility to be closest to its customer base, quantitative methods can be very useful. In these cases, one must specify how distance is measured. Straight-line distance (also known as Euclidean distance) measures the shortest distance between two points. However, straight-line distance is not always the most appropriate measure. For example, when locating a firehouse, one must take into account the layout of streets. Using rectilinear distance (as measured by only horizontal and vertical movements) would make more sense in this context. Another consideration is that not all customers are of equal size. For example, a bakery would make larger deliveries to a supermarket or warehouse store than to a convenience store. Here one would use a weighted distance criterion. In the remainder of this chapter, we review several quantitative techniques for finding the best location of a single facility under various objectives. Chapter 11 Purpose To understand what quality means in the operations context, how it can be measured, and how it can be improved.Key Points 1. What is quality? While we all have a sense of what we mean by quality, defining it precisely as a measurable quantity is not easy. A useful definition is conformance to specifications. This is something that can be measured and quantified. If it can be quantified, it can be improved. However, this definition falls short of capturing all the aspects of what we mean by quality and how it is perceived by the customer.2. Statistical process control. Statistical methods can assist with the task of monitoring quality in the context of manufacturing. The underlying basis of statistical control charts is the normal distribution. The normal distribution (bell-shaped distribution) has the property that the mean plus and minus two standard deviations (μ ± 2σ) contains about 95 percent of the population, and the mean plus and minus three standard deviations (μ ± 3σ) contains more than 99 percent of the population. It is these properties that form the basis for statistical control charts. Consider a manufacturing process producing an item with a measurable quantity that must conform to a given specification. One averages the measurements of this quantity in subgroups (typically of size four or five). The central limit theorem guarantees that the distribution of the average measurement will be approximately normally distributed. If the average of a subgroup lies outside two or three sigma limits of the normal distribution, it is unlikely that this deviation is due to chance. This signals an out-of-control situation, which might require intervention into the process. This is the basis for the  While the 3. The p and c charts. The The c chart is based on the Poisson distribution. The Poisson distribution describes events that occur completely at random over time or space. In the statistical quality control context, consider a situation where a certain number of defects are acceptable, such as minor dents on an automobile, but too many are considered unacceptable. In this case, the c chart would be an appropriate means of monitoring the process. The parameter c is the average rate of occurrence of flaws, and an out-of-control signal is tripped when the observed value of c is too high. Note that both the p and c charts are typically implemented with a normal distribution, since, under the right circumstances, the normal distribution provides a good approximation to both the binomial and Poisson distributions. 4. Economic design of control charts. Statistical quality control requires several steps, each of which incurs a different cost. First, there's the cost of inspecting the items. For 5. Acceptance sampling. The second part of this chapter deals with acceptance sampling. Acceptance sampling occurs after a lot of items is produced, rather than during the manufacturing process. It can be performed by the manufacturer or by the consumer. In most cases, 100 percent inspection of items is impractical, impossible, or too costly. For these reasons, a more common approach is to sample a subset of the lot and choose to accept or reject the lot based on the results of the sampling. The most common sampling plans are (1) single sampling, (2) double sampling, and (3) sequential sampling. In the case of single sampling, one samples n items from a lot of N items (where n < N) and rejects the lot if the number of defects exceeds a specified level. Double sampling means that if the number of defectives falls between two prespecified limits (that is, is neither very high nor very low), one samples again to determine the fate of the lot. In sequential sampling one decides either to accept the lot, reject the lot, or continue sampling after each item is sampled. The appropriate limits for each of these tests are based on the underlying probability distributions and specification of acceptable levels of Type 1 error (α). 6. Total quality management. As the quality movement began to take hold in the United States and other parts of the world, one way of describing an organization's commitment to quality was total quality management (TQM). Briefly, this is the complete commitment of all parts of a firm to the quality mission. An important part of TQM is listening to the customer. This process includes customer surveys and focus groups to find out what the customer wants, distilling this information, prioritizing customer needs, and linking those needs to the design of the product. One means of accomplishing the last item on the list is quality function deployment (QFD). Several agencies worldwide promote quality in their respective countries through formal recognition. This process was started in Japan with the Deming Prize, established and funded by quality guru W. Edwards Deming. In the United States, we recognize outstanding quality with the Baldrige Prize. Another important development is the International Standards Organization's certification, ISO 9000, which requires firms to clearly document their policies and procedures. While the certification process can be costly in both time and money, it is often required to do business in many countries. The chapter concludes with a discussion of designing for quality. By putting a greater investment up front in sound product design, the consumer will be rewarded with superior products and the firm will be rewarded with customer loyalty. Chapter 12 Purpose To gain an appreciation of the importance of reliability, to understand the mechanisms by which products fail, and to acquire an understanding of the mathematics underlying these processes.Key Points 1. Preparation. The topics in this chapter (reliability theory, warranties, and age replacement) are rarely treated in texts on operations. They are included here because of their importance and relevance to the quality movement. However, the mathematics of reliability is complex. One must have a basic understanding of random variables, probability density and distribution functions, and elementary stochastic processes. Several of these methods were also used in Chapter 5 and in Supplement 2 on queuing, appearing after Chapter 8. I suggest the reader carefully review the discussion of the exponential distribution presented there.2. Reliability of a single component. Consider a single item whose time of failure cannot be predicted in advance; that is, it is a random variable, T. We assume that we know both the distribution function and density functions of T: F(t) and f(t), respectively. Several important quantities associated with T include the survival function R(t) = 1 - F(t), which is the probability that the item survives beyond t, and the failure rate function, defined as r(t) = f(t) / R(t). An important case occurs when the failure rate function is a constant independent of t. This results in the failure time distribution having the exponential distribution. The exponential distribution is the only one possessing the memoryless property. In this context it means that the item is neither getting better nor getting worse with age. Decreasing and increasing failure rate functions, respectively, represent the cases where the reliability of an item is improving or declining with age. The Weibull distribution is a popular choice for representing both increasing and decreasing failure rate functions. 3. The Poisson process in reliability modeling. The Poisson process is perhaps the most important stochastic process for applications. When interfailure times are independent and identically distributed (IID) exponential random variables, one can show that the total number of failures up to any point t follows a Poisson distribution, and the time for n failures follows an Erlang distribution. Because the exponential distribution is memoryless, this process accurately describes events that occur completely at random over time. 4. Reliability of complex equipment. Items prone to failure are generally constructed of more than a single component. In a series system, the system fails when any one of the components fails. In a parallel system, the system fails only when all components fail. A third possibility is a K out of N system. Here the system functions as long as at least K components function. In this section, we show how to derive the time to failure distributions for these systems based on the time to failure distributions of the components comprising the systems. 5. Maintenance models. Preventive maintenance means replacing an item before it fails. Clearly, this only makes sense for items that are more likely to fail as they age. By replacing items on a regular basis before they fail, one can avoid the disruptions that result from unplanned failures. Based on knowledge of the items' failure mechanisms and costs of planned and unplanned replacements, one can derive optimal replacement strategies. The simplest case gives a formula for optimal replacement times, which is very similar to the EOQ formula derived in Chapter 4. 6. Warranties. A warranty is an agreement between the buyer and seller of an item in which the seller agrees to provide restitution to the buyer in the event the item fails within the warranty period. Warranties are common for almost all consumer goods, and extended warranties are a big business. In this section, we examine two kinds of warranties: the free replacement warranty and the pro rata warranty. The free replacement warranty is just as it sounds: the seller agrees to replace the item when it fails during the warranty period. In the case of the pro rata warranty, the amount of restitution depends on the remaining time of the warranty. (Pro rata warranties are common for tires, for example, where the return depends on the remaining tread on the tire.) 7. Software reliability. Software is playing an increasingly important role in our lives. With the explosive growth of personal computers, the market for personal computer software has become enormous. Microsoft took advantage of this growth to become one of the world's major corporations within a decade of its founding. There is a lot more to the software industry than personal computers, however. Large databases, such as those managed by the IRS or your state Department of Motor Vehicles require massive information retrieval systems. Some predicted that Ronald Reagan's Star Wars missile defense system was doomed to failure because it would be impossible to design reliable software for it. Software failures can be just as catastrophic as hardware failures, causing major systems to fail. |
